Self learning Pac-Man player, using reinforcement learning
01 Jun 2015 | reinforcement learning neural network This project was performed togehter with Maco Morik.
This project was performed togehter with Maco Morik.
The goal of the project was to build a Pac-Man player that learns to play by exploring. The player was implemented using approximate Q-learning. We used a neural network (7 inputs, 1 hidden layer of 50 neurons, and 1 output) to approximate the Q function. The inputs were an action (e.g. top/left/bottom/right) along side 6 features extracted from the game state. The used features are:
- Distance to closed food pill
- Remaining food pills
- Distance to the closest non-scared ghost
- Distance to the closest scared ghost
- time left of the closes scared ghost
- Ghost presence in a neighboring location
Below is showing the game score (averaged over 30 game episodes) during training. After 400 games, the player seems to have converged to some playing strategy (policy).
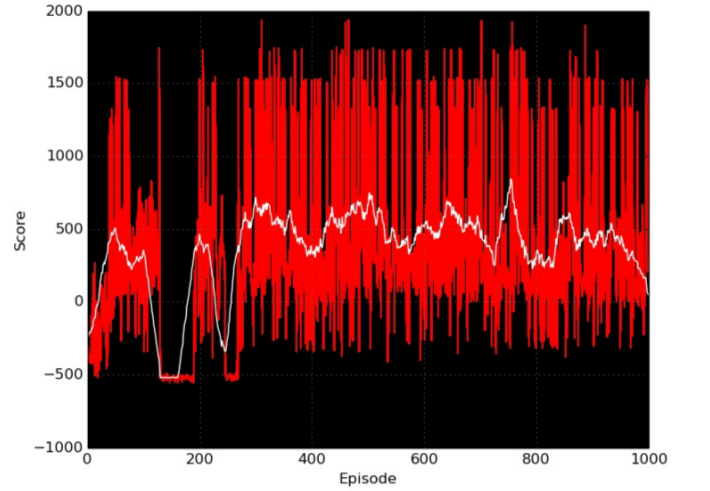
When tested in 50 games, the player achieved a game win rate of 97% against random ghosts, and 53% against intelligent ghosts that chases Pack-man (player with Q-function approximated with a linear regression model achieved a game win rate of 92% and 53% for the two scenarios). The neural network has improvement over the linear model, but not a significant one. This most likely due to the fact that the game is state is approximated with some features that do not capture all the aspects of the game state (i.e. there is no feature indicating direction of ghosts movement). Deep neural networks automatically extract “good” feature representations from the raw inputs, and hence using them as approximator for the Q function results in a more powerful agents (given that they were trained correct).
Comments