Building a video search engine exploiting the video content
20 May 2016 | elasticsearch kibana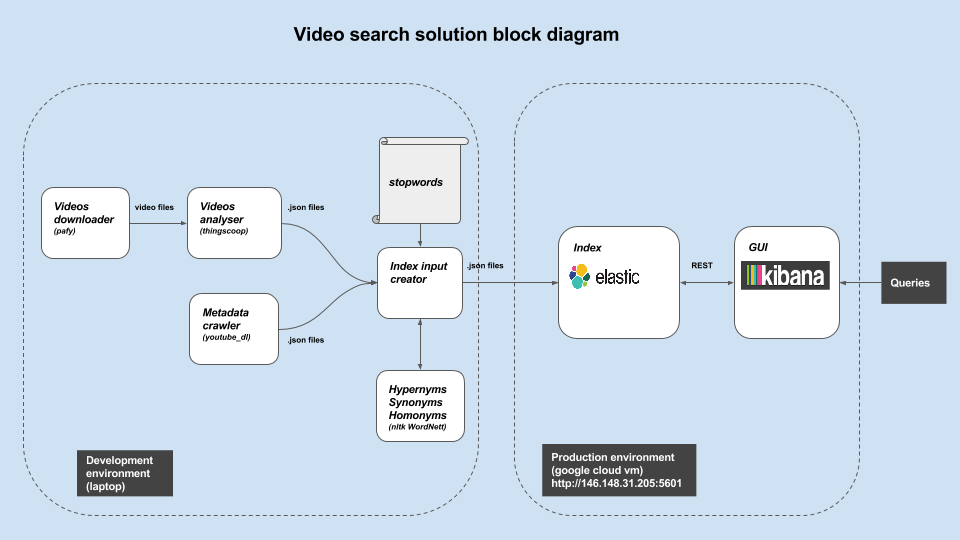 I was part of a group that did this work. The other group members are (Evan Durfee, Magnús Þór Benediktsson, Nick Anderson and Sofia Broomé);
I was part of a group that did this work. The other group members are (Evan Durfee, Magnús Þór Benediktsson, Nick Anderson and Sofia Broomé);
When it comes to indexing video databases (e.g. youtube), the majority of existing search engines uses the textual metadata associated with the videos (i.e. title, description, etc.) to index them (I don’t know about youtube). This metadata includes things like the title of the video, the description, the uploader, the upload date, etc. The quality of returned videos (in term of satisfying the user need) for search queries depends to a large extend on how good the videos metadata describes to the videos.
Different from traditional video search engines (in the previous paragraph), the objective of this work was to build a video search engine that uses the video content (not the metadata) to index the videos, assuming the video content better describes the videos.
The overall idea is to extract a textual representation for each video (see below how), and use the words in the generated text as tokens to index the videos in Elasticsearch. The indexing pipeline of our search engine is illustrated by the shown diagram. Below is a description for each box:
- Video downloader : for evaluating the search engine we indexed videos from youtube, and we used the the pafy python library for that.
- Videos analyzer : We used Thingscoop library to extract texts from the videos. For each video, Thingscoop looks at the video one frame at a time, and use a deep convolutional neural network (CNN) to predict the objects present in the frame image (car, boy, dog, etc…). Thingscoop comes with a couple of pretrained deep CNNs.
- Stop words removal : The CNNs used by Thingscoop is trained for detecting general objects (either Imagenet or Google places datasets), and as a result several general words (like instrument or device) appear in almost all the generated video texts. Such words increase the generated index size which providing no “discriminative” value in specifying the target videos when used as search terms. As a result we treated these words as stop words and remove them from the text extracted from the videos.
- Index expansion: To improve the quality of the returned query results (recall and precision), the terms on each video text were expanded by their hypernyms and synonyms. This way a search with the term “vehicle” or “car” will return the same set of videos even though only “car” (or conversely “vehicle”) was used to index these videos.
- To build the Elasticsearch index, a JSON document (with several fields including the video title, the video link, the text representation (from previous step) etc…) is created for each video, and then indexed using the Elasticsearch bulk api.
- Kibana provided a browser interface for issuing queries towards the built index.
We did not have enough time to compare the built search engine to a traditional one (a one uses the video metadata for indexing) in term of recall and precision, but the performed evaluation (recall and precision for a set of 5 queries) encourages a further more thorough investigation of such approach. One limitation of this approach is that, the generated video text (Thingscoop output) impacts the performance of the search engine; Thingscoop output is comprised of the objects present in the videos (cars, dog, human, etc). Using captions generated from the videos (using something like this) would result in a better search engine.
Comments