20 May 2016
|
elasticsearch
kibana
 I was part of a group that did this work. The other group members are (Evan Durfee, Magnús Þór Benediktsson, Nick Anderson and Sofia Broomé);
I was part of a group that did this work. The other group members are (Evan Durfee, Magnús Þór Benediktsson, Nick Anderson and Sofia Broomé);
When it comes to indexing video databases (e.g. youtube), the majority of existing search engines uses the textual metadata associated with the videos (i.e. title, description, etc.) to index them (I don’t know about youtube). This metadata includes things like the title of the video, the description, the uploader, the upload date, etc. The quality of returned videos (in term of satisfying the user need) for search queries depends to a large extend on how good the videos metadata describes to the videos.
Different from traditional video search engines (in the previous paragraph), the objective of this work was to build a video search engine that uses the video content (not the metadata) to index the videos, assuming the video content better describes the videos.
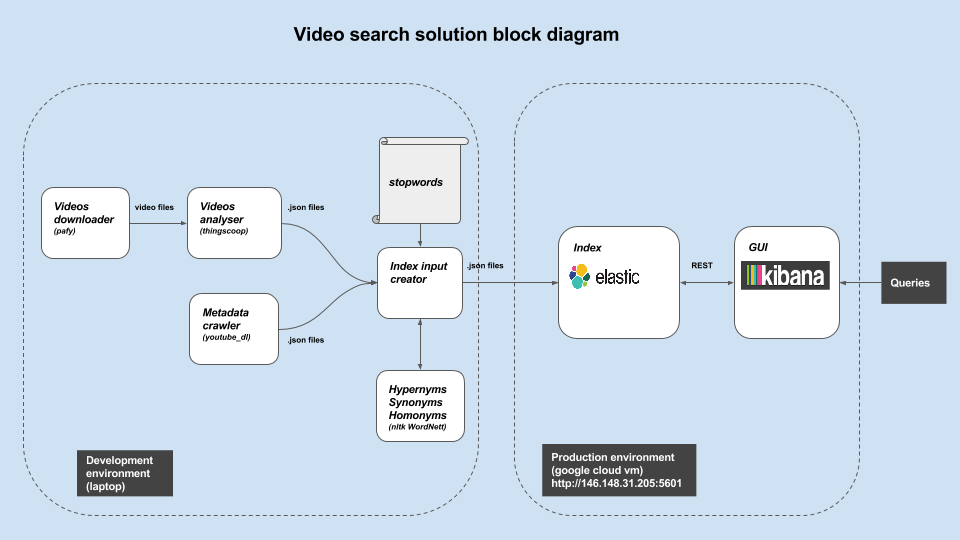
The overall idea is to extract a textual representation for each video (see below how), and use the words in the generated text as tokens to index the videos in Elasticsearch. The indexing pipeline of our search engine is illustrated by the shown diagram. Below is a description for each box:
- Video downloader : for evaluating the search engine we indexed videos from youtube, and we used the the pafy python library for that.
- Videos analyzer : We used Thingscoop library to extract texts from the videos. For each video, Thingscoop looks at the video one frame at a time, and use a deep convolutional neural network (CNN) to predict the objects present in the frame image (car, boy, dog, etc…). Thingscoop comes with a couple of pretrained deep CNNs.
- Stop words removal : The CNNs used by Thingscoop is trained for detecting general objects (either Imagenet or Google places datasets), and as a result several general words (like instrument or device) appear in almost all the generated video texts. Such words increase the generated index size which providing no “discriminative” value in specifying the target videos when used as search terms. As a result we treated these words as stop words and remove them from the text extracted from the videos.
- Index expansion: To improve the quality of the returned query results (recall and precision), the terms on each video text were expanded by their hypernyms and synonyms. This way a search with the term “vehicle” or “car” will return the same set of videos even though only “car” (or conversely “vehicle”) was used to index these videos.
- To build the Elasticsearch index, a JSON document (with several fields including the video title, the video link, the text representation (from previous step) etc…) is created for each video, and then indexed using the Elasticsearch bulk api.
- Kibana provided a browser interface for issuing queries towards the built index.
We did not have enough time to compare the built search engine to a traditional one (a one uses the video metadata for indexing) in term of recall and precision, but the performed evaluation (recall and precision for a set of 5 queries) encourages a further more thorough investigation of such approach. One limitation of this approach is that, the generated video text (Thingscoop output) impacts the performance of the search engine; Thingscoop output is comprised of the objects present in the videos (cars, dog, human, etc). Using captions generated from the videos (using something like this) would result in a better search engine.
20 Oct 2015
|
git
Jira
!!!WORK IN PROGRESS
 An implementation of a Google algorithm developed by its engineering tools team for predicting faults in source code files. Here I’ll describe the ongoing implementation at my workplace where we use Git to version-control our code and Jira to track our features, improvements and bug fixes.
An implementation of a Google algorithm developed by its engineering tools team for predicting faults in source code files. Here I’ll describe the ongoing implementation at my workplace where we use Git to version-control our code and Jira to track our features, improvements and bug fixes.
To be continued …
01 Jun 2015
|
reinforcement learning
neural network
 This project was performed togehter with Maco Morik.
This project was performed togehter with Maco Morik.
The goal of the project was to build a Pac-Man player that learns to play by exploring. The player was implemented using approximate Q-learning. We used a neural network (7 inputs, 1 hidden layer of 50 neurons, and 1 output) to approximate the Q function. The inputs were an action (e.g. top/left/bottom/right) along side 6 features extracted from the game state. The used features are:
- Distance to closed food pill
- Remaining food pills
- Distance to the closest non-scared ghost
- Distance to the closest scared ghost
- time left of the closes scared ghost
- Ghost presence in a neighboring location
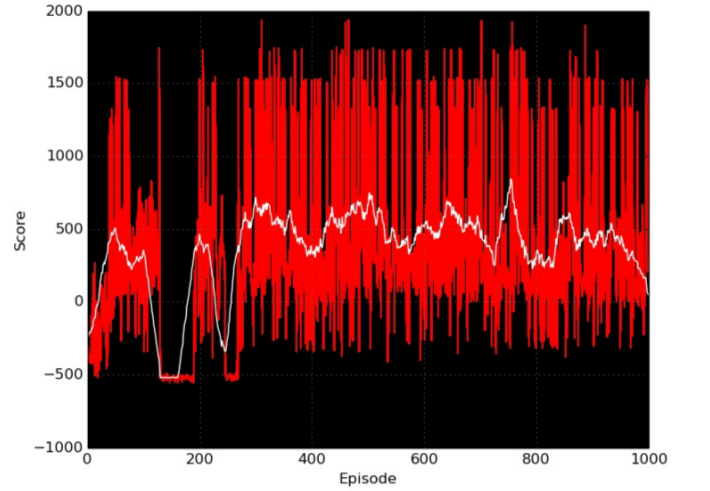
Below is showing the game score (averaged over 30 game episodes) during training. After 400 games, the player seems to have converged to some playing strategy (policy).
When tested in 50 games, the player achieved a game win rate of 97% against random ghosts, and 53% against intelligent ghosts that chases Pack-man (player with Q-function approximated with a linear regression model achieved a game win rate of 92% and 53% for the two scenarios). The neural network has improvement over the linear model, but not a significant one. This most likely due to the fact that the game is state is approximated with some features that do not capture all the aspects of the game state (i.e. there is no feature indicating direction of ghosts movement). Deep neural networks automatically extract “good” feature representations from the raw inputs, and hence using them as approximator for the Q function results in a more powerful agents (given that they were trained correct).
References
30 May 2015
|
speech recognition
Caffe
 This work was done together with Omar El-Shenawy as part of an speech recognition course at KTH.
This work was done together with Omar El-Shenawy as part of an speech recognition course at KTH.
Until before the rise of deep learning (DL), state of the art speech recognition systems were dominated by Hidden Markov Models (HMM) coupled with Gaussian Mixture Models (GMM). GMMs (used as emission probabilities for the HMMs) modeled the phonemes probabilities given an acoustic input (a sound wave represented as a time-series), while the HMMs modeled sequences of phonemes (which can be full words) (sequence decoder). Thanks to deep learning, speech recognition systems performance improved significantly and that is primarily to using deep neural networks for phonemes modeling instead of the GMMs.
A Google paper (lost the reference; will look for it) described how they trained a deep neural network to recognize spoken words given the spectrogram representation of the words acoustic signal. So the words acoustic signal are first converted into spectrogram images, which are then used as inputs to the deep network.
Inspired by Google’s work, we devised a similar approach for the phoneme prediction task. Each phoneme acoustic signal is converted into an spectrogram image, and used resulting images as input to train a deep convolutional neural network (CNN) to predict the phoneme class given the spectrogram input. This CNN could then replace a GMM in a decoder; i.e. use the CNN for the HMM emission probabilities. Being translational invariant and capable of modeling correlations, CNNs sound a good candidate for speech where spectral variations (resulting from the different speaking styles) are a norm. Following are some details of our method:
Dataset
To investigate the model, we extracted phonemes from the TIMIT dataset. We used 39 out of the 61 phonemes in the datasets.
Spectrogram creation
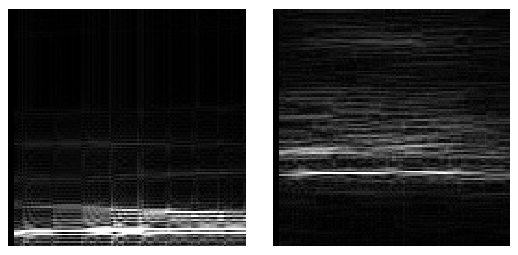
Each phoneme acoustic signal is first split into 16ms overlapped Hanning windows (15.5ms overlap). Fast Fourier Transform are then applied on each windows to create the spectrograms. The spectrograms were generated with utilizing part of this project. Sample spectrograms for phonmes “sh” and “ao” are shown at the begining of this post.
CNN training
We did choose a CNN architecture similar to the famous AlexNet. We used Digits framework (uses Caffe in the backend) for training the network.
We achieved a prediction accuracy of 79% on the test set (on 39 out of 61 phonemes). We thought a better results could be achieved if the network was trained for more iterations (we trained for 50 epocs in this work). Also the performance can improve of more data (all the phonemes) is used to train the network. We were also were not sure how effective the representation in discriminating between the phonemes. This could have been studied further by a help of a confusion matrix (for example).
20 Oct 2014
|
CI
CD
Eiffel
Jenkins
Artifactory
Large scale end-2-end CI/CD pipeline using Eiffel framework.
To be continued …