Phoneme prediction using Deep convolutional neural networks
30 May 2015 | speech recognition Caffe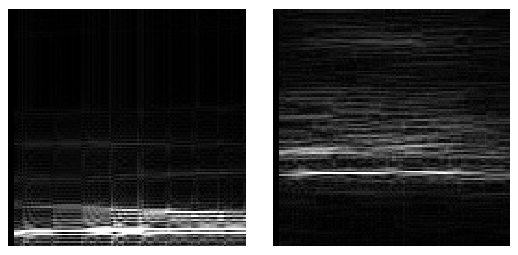 This work was done together with Omar El-Shenawy as part of an speech recognition course at KTH.
This work was done together with Omar El-Shenawy as part of an speech recognition course at KTH.
Until before the rise of deep learning (DL), state of the art speech recognition systems were dominated by Hidden Markov Models (HMM) coupled with Gaussian Mixture Models (GMM). GMMs (used as emission probabilities for the HMMs) modeled the phonemes probabilities given an acoustic input (a sound wave represented as a time-series), while the HMMs modeled sequences of phonemes (which can be full words) (sequence decoder). Thanks to deep learning, speech recognition systems performance improved significantly and that is primarily to using deep neural networks for phonemes modeling instead of the GMMs.
A Google paper (lost the reference; will look for it) described how they trained a deep neural network to recognize spoken words given the spectrogram representation of the words acoustic signal. So the words acoustic signal are first converted into spectrogram images, which are then used as inputs to the deep network.
Inspired by Google’s work, we devised a similar approach for the phoneme prediction task. Each phoneme acoustic signal is converted into an spectrogram image, and used resulting images as input to train a deep convolutional neural network (CNN) to predict the phoneme class given the spectrogram input. This CNN could then replace a GMM in a decoder; i.e. use the CNN for the HMM emission probabilities. Being translational invariant and capable of modeling correlations, CNNs sound a good candidate for speech where spectral variations (resulting from the different speaking styles) are a norm. Following are some details of our method:
Dataset
To investigate the model, we extracted phonemes from the TIMIT dataset. We used 39 out of the 61 phonemes in the datasets.
Spectrogram creation
Each phoneme acoustic signal is first split into 16ms overlapped Hanning windows (15.5ms overlap). Fast Fourier Transform are then applied on each windows to create the spectrograms. The spectrograms were generated with utilizing part of this project. Sample spectrograms for phonmes “sh” and “ao” are shown at the begining of this post.
CNN training
We did choose a CNN architecture similar to the famous AlexNet. We used Digits framework (uses Caffe in the backend) for training the network.
We achieved a prediction accuracy of 79% on the test set (on 39 out of 61 phonemes). We thought a better results could be achieved if the network was trained for more iterations (we trained for 50 epocs in this work). Also the performance can improve of more data (all the phonemes) is used to train the network. We were also were not sure how effective the representation in discriminating between the phonemes. This could have been studied further by a help of a confusion matrix (for example).
Comments